 Coding N Concepts
Coding N Concepts Top Microservices Interview Questions
Top Microservices Interview Questions
These Microservices based interview questions are based on my personal interview experience and feedback from other interviewees. These questions verifies your theoretical as well as practical knowledge about microservices. Keep following this post for regular updates.
Q1. What do you understand by microservices?
When you break an entire application architecture into smaller services where
- Each service is independently serves a functionality of that application
- Each service has their own development, build process, deployment and testing cycle
This kind of setup is known as microservices based architecture.
Q2. What are the advantage of microservices over monolithic application?
| Monolithic application | Microservices based application |
|---|---|
| Single code base for entire application so one small code change requires the build process, testing and deployment of entire application. | Each microservice can be developed, build, deployed and tested independently and code change in one microservice doesn’t affect entire application. |
| Single code base for entire application so can be written in one technology. | Each Microservice can be written in different technology stack like Java, Scala, Python, NodeJs etc. |
| Monolithic application can be scaled vertically by adding more servers. | It can be scaled both vertically and horizontally by adding more servers and running multiple copies of each microservice behind a load balancer. |
| If something goes wrong with monolithic application and its down means whole application is down. | It is fault tolerant and continue to run with limited functionality if something goes wrong in few microservices and they are down. |
Q3. You have to migrate an existing monolithic application to microservices. What will be your approach?
Migrating from monolithic application to microservices is a long term process where we gradually :-
- Pick one functionality of monolithic application
- Copy the functionality from monolithic application in terms of source code, database, schema
- Create an independent microservice which serves the same functionality
- Integrate monolithic application with this microservice
- Remove the source code, database, schema etc from monolithic application when integration with microservice is successful.
Repeat the above 5 steps until our entire monolithic application is converted into microservices.
Q4. What are the best practices to design microservices based application ?
These are few best practices to design microservice:-
- One functionality one microservice
- Separate data source for each microservice
- Follow twelve factors from The Twelve-Factor App
Q5. What are the challenges in microservices based application ?
The challenges with microservices are as follows:-
- Require good investment for infrastructure setup.
- It is a nightmare to manage development, build, test, deployment and release cycles manually. DevOps is must to implement CI/CD (Continuous integration, continuous delivery) automation.
- Difficult to troubleshoot or debug an issue spanning across multiple microservices.
- Overhead of inter communication between microservices
- Challenges in development and testing where two or more microservices are involved.
- Difficult to make configuration change across large fleet of microservices.
- Operation and maintenance overhead.
- Challenges comes with distributes system such as Network latency, fault tolerance, distributed transactions, unreliable networks, handling asynchronous operations.
Q6. How do you troubleshoot an issue using logs in microservices based application ?
For troubleshooting an issue using logs in microservices based application,
- We should have a centralized logging system where each microservice push their logs to
SplunkorELK (Elastic Logstash Kibana)and we can use their built in dashboards to look at the logs for debugging. - We can generate a requestId for each external request, which is passed to all the microservices which are involved in handling the request. Include this requestId in all log messages pushed to splunk or ELK. We can troubleshoot any request end to end using this requestId if something goes wrong.
Also read how to create custom logger to print API request and response along with incoming requestId
Q7. How do you manage configuration in microservices based application ?
If we want to modify the configuration for a microservice that has been replicated a hundred times (one hundred processes are running). If the configuration for this microservice is packaged with the microservice itself, we’ll have to redeploy each of the one hundred instances. This can result in some instances using the old configuration, and some using the new one, at some point. Moreover, sometimes microservices use external connections which, for example, require URLs, usernames, and passwords. If you want to update these settings, it would be useful to have this configuration shared across services.
We use externalize configuration to solve this problem by keeping the configuration information in an external store such as github, database, filesystem, or environment variables or even a configuration server. At startup, microservices load the configuration from the external store or configuration server.
Netflix Archaius and Spring Cloud Config Server provides ready made solution for externalize configuration.
Q8. How do microservices communicate with each other ?
Microservices often communicate with each other using RESTful APIs over HTTP. The communication can be broadly divided into two categories:-
RestTemplate,WebClient,FeignClientcan be used for synchronous communication between microservicesActiveMQ,RabbitMQ,Kafkacan be used for asynchronous communication across microservices.
Q9. How do you manage authentication and authorization in microservices based application ?
Session based authentication works well with stateful monolith applications but token based authentication and authorization is recommended for microservices based application to maintain the statelessness. A typical flow of token based authentication is as follows:-
- User sends a login request with username and password.
- If you are using Api gateway then it is responsible for generating the token and hence authentication. It achieves this by communicating with authorization and users service.
- User receives a token on successful login which is typically stored in browser cookies. Token holds the user’s information in the encrypted format.
- When user make any request of resources, this token is sent in Authorization header of each request.
- Microservices decrypts the token and evaluate user information to authorize for resource access and send the response accordingly.
JWT
JWT (Json Web Token) is widely used token based authentication mechanism. JWT consist of three parts:
- header contains type, fixed value JWT and the hashing algorithm used by JWT
{ "typ": "JWT", "alg": "HS256" } - payload typically contains user authorization related information such as id, name, roles, permissions etc. It also contains the expiry period of token.
{ "id": 12345, "name": "admin_user", "email": "admin_user@organization.com", "roles": ["admin"], "permissions": ["can_access_resource_1", "can_access_resource_2"] } - signature is required to verify the authenticity of token. It consists of the encoded header, the payload and the secret key.
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret )
All microservices can verify the token based on the signature so there are no further calls to the authorization server after login.
Authentication & Authorization flow using JWT
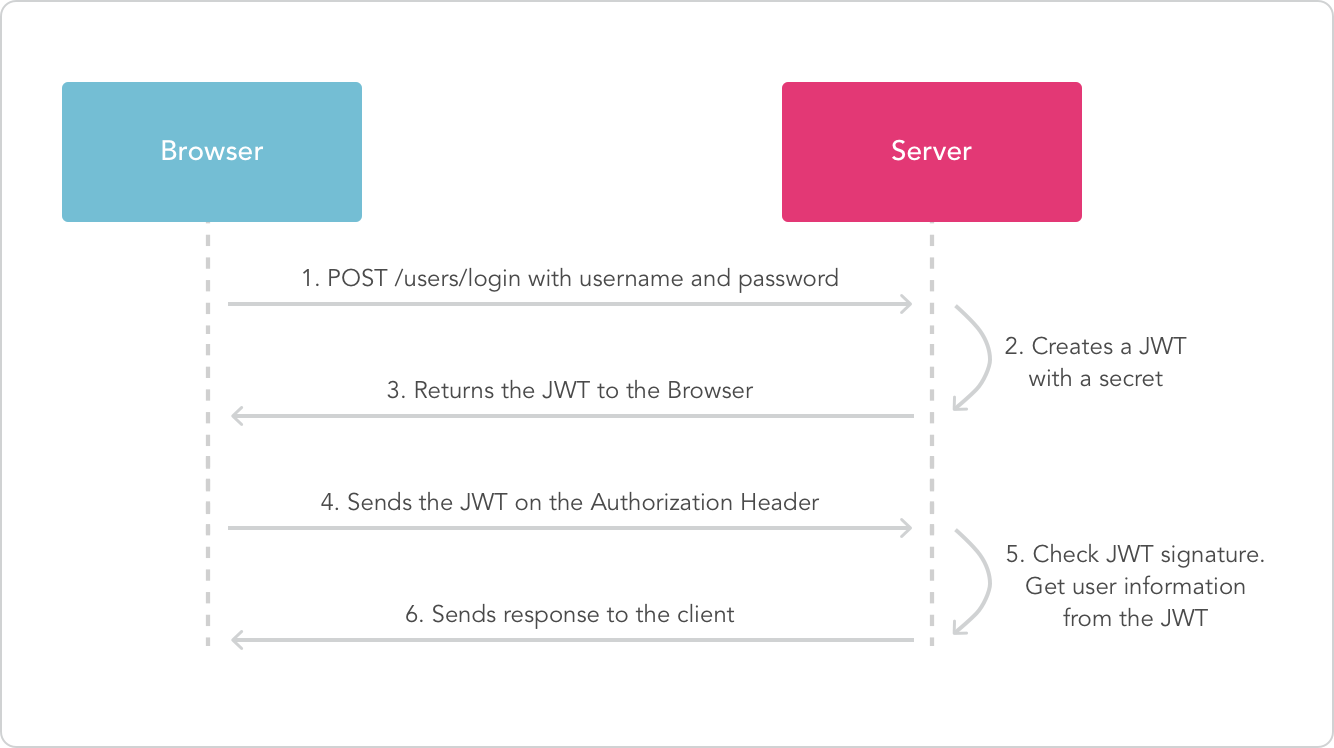
User Authentication & Authorization flow using JWT
Q10. How do you handle distributed transaction across microservices ?
Transactions are easy to handle in monolithic application with single code base, single data source and deployment on single server whereas it becomes a challenge to handle a distributed transaction across microservices where each microservice has its own data store and deployed on different servers. There are different approach to handle distributed transactions:
1. Avoid if at all possible
First and foremost approach is to avoid them completely.
If we can not avoid transaction between two microservices. Just think,
Are they meant to be together? Merge them in one microservice?
Can we redesign them in such a way so that transaction becomes unnecessary.
2. Two-phase commit protocol (2PC)
Two phase commit protocol commits into 2 steps:
- Prepare Phase The transaction coordinator send a prepare command to each participant in the transaction Each participant then checks if they could commit the transaction.
- Commit Phase If that’s the case, they respond with “prepared” and the transaction coordinator sends a commit command to all participants. The transaction was successful, and all changes get committed.
or Rollback Phase If any of the participant doesn’t answer the prepare command or responds with “failed”, the transaction coordinator sends an abort command to all participants. This rolls back all the changes performed within the transaction.
Its an old, complicated and slow approach because of all the coordination things and should be avoided.
3. The Saga pattern
Saga is one of the well known pattern for distributed transactions.
A saga is a sequence of local transactions where each transaction updates data within a single service. The first transaction is initiated by an external request corresponding to the system operation, and then each subsequent step is triggered by the completion of the previous one.
There are a two ways to implement a saga transaction:-
Events/Choreography
In this approach there is no central coordination, executes a transaction and then publishes an event. This event is listened by one or more services which execute local transactions and publish (or not) new events.
The distributed transaction ends when the last service executes its local transaction and does not publish any events or the event published is not heard by any of the saga’s participants.
Let’s see how it would look like in our e-commerce example:
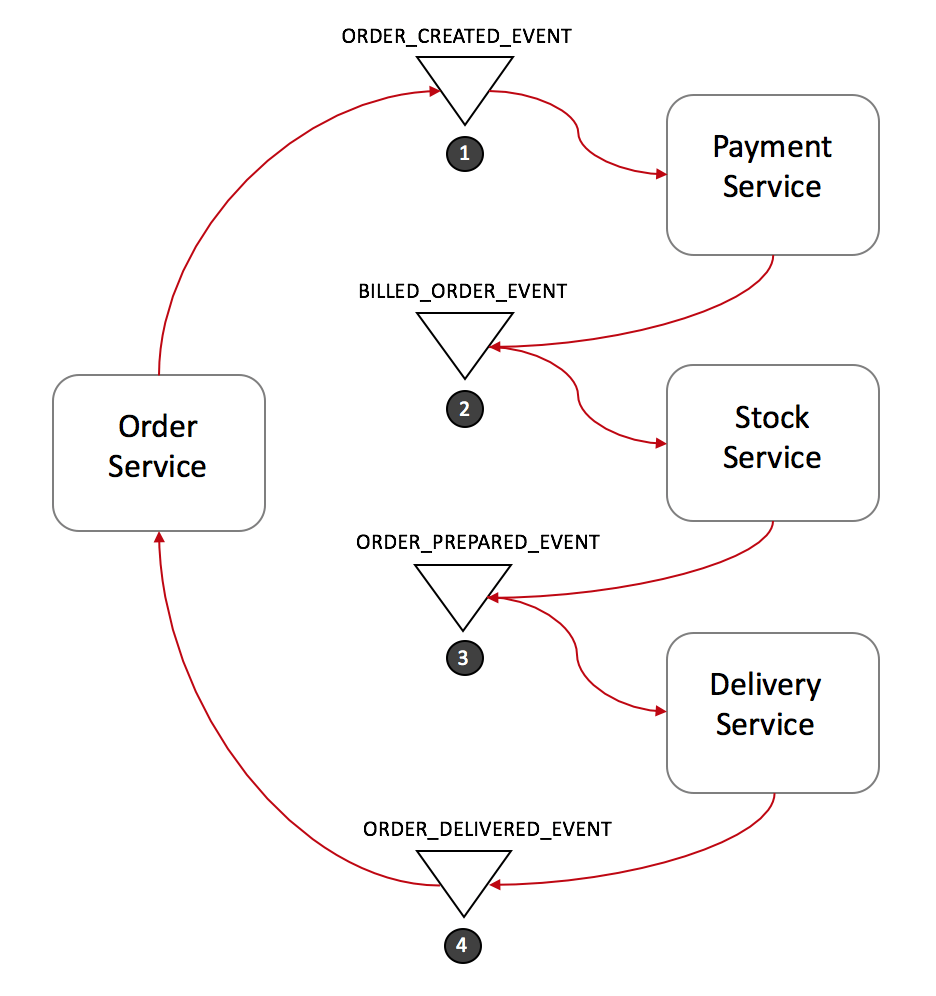
Event Saga Pattern (Success Use Case)
- Order Service saves a new order, set the state as pending and publish an event called ORDER_CREATED_EVENT.
- The Payment Service listens to ORDER_CREATED_EVENT, charge the client and publish the event BILLED_ORDER_EVENT.
- The Stock Service listens to BILLED_ORDER_EVENT, update the stock, prepare the products bought in the order and publish ORDER_PREPARED_EVENT.
- Delivery Service listens to ORDER_PREPARED_EVENT and then pick up and deliver the product. At the end, it publishes an ORDER_DELIVERED_EVENT
- Finally, Order Service listens to ORDER_DELIVERED_EVENT and set the state of the order as concluded.
In the case above, if the state of the order needs to be tracked, Order Service could simply listen to all events and update its state.
Rollback
For Rollback, you have to implement another operation/transaction to compensate for what has been done before.
Suppose that Stock Service has failed during a transaction. Let’s see what the rollback would look like:
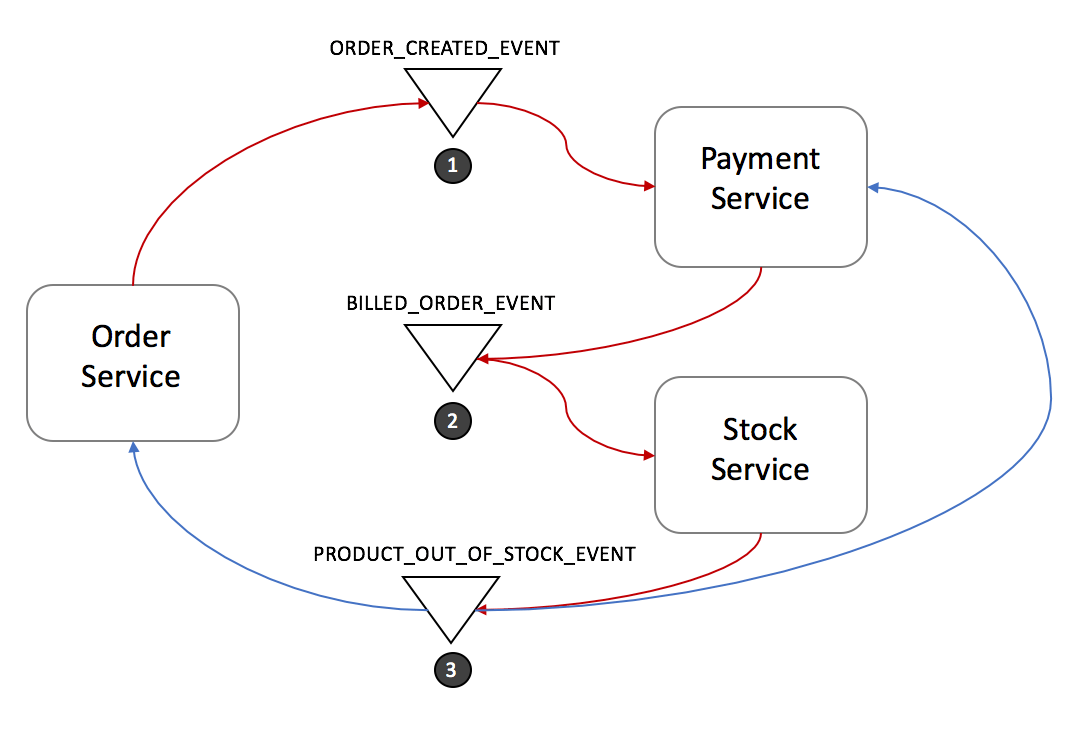
Event Saga Pattern (Failure Use Case)
- Stock Service produces PRODUCT_OUT_OF_STOCK_EVENT;
- Both Order Service and Payment Service listen to the previous message:
- Payment Service refund the client
- Order Service set the order state as failed
Note that it is crucial to define a common shared ID for each transaction, so whenever you throw an event, all listeners can know right away which transaction it refers to.
It is simple, easy to understand, does not require much effort to build.
Command/Orchestration
when a coordinator service is responsible for centralizing the saga’s decision making and sequencing business logic.
Please read this post for for more details on Command/Orchestration pattern
Q11. What is service discovery pattern in microservices ?
Service discovery is a pattern in microservices which solves the problem of service registry and discovery.
Service Discovery registers entries of all of the services running under that application. Whenever a service is up and running, it registers itself with discovery server and thereafter discovery server polls those services to check their heartbeats if they are up or down.
When one service (client) wants to make a request to another service, it can talk to discovery server to locate the service in two ways:-
1. Client side service discovery
Client asks the address of service from discovery server and then once client gets the address, it requests to the service directly.
Client ask service_address ⟹ Discovery Server give service_address ⟹ Client make request ⟹ Service return response ⟹ Client
Netflix Eureka is one of the implementation of client side service discovery pattern.
2. Server side service discovery
Client request to discovery server which redirect the request to appropriate service and get the response back and redirect to client.
Client make request ⟹ Discovery Server redirect request ⟹ Service return response ⟹ Discovery Server redirect response ⟹ Client
Q12. What is circuit breaker pattern in microservices ?
Circuit breaker is popular pattern for fault tolerance in microservices.
Problem
Services sometimes call other services to handle requests. There is always a possibility that the other service is unavailable or taking longer time to respond. Precious resources such as threads might be consumed in the caller service while waiting for the other service to respond. This might lead to resource exhaustion, which would make the calling service unable to handle other requests. The failure of one service can potentially cascade to other services throughout the application.
Solution
Thats where circuit breaker comes into play to prevent service failure from cascading to other services.

Circuit Breaker
Consider one service calling another service like an electric circuit breaker. When all works fine circuit breaker is closed.
-
When service detects that something is wrong with another service, the circuit breaks (circuit breaker is open).
✦ When to break circuit?
✓ When m out of last n requests failed (When 3 out of last 5 requests failed)
✓ Request is considered failed if it responds after timeout period of t seconds (say 2s) -
Once circuit breaks, service do not attempt to call another service.
✦ What to do when circuit breaks?
● throw an error or
● return a fallback “default” response or
● serve previous responses from cache -
After waiting for sleep window of x seconds (say 10s), service attempts to call another service (circuit breaker is half open)
● If request fails then circuit breaks (circuit breaker is open). It repeats step 2 and 3 again.
● If gets a successful response back then circuit gets closed. Resume the requests again. All works fine.
Netflix Hystrix is one of the implementation of circuit breaker pattern.
Q13. What is API gateway pattern in microservices ?
API gateway pattern is a good approach to consider when building large or complex microservices based application.
API Gateway Flow
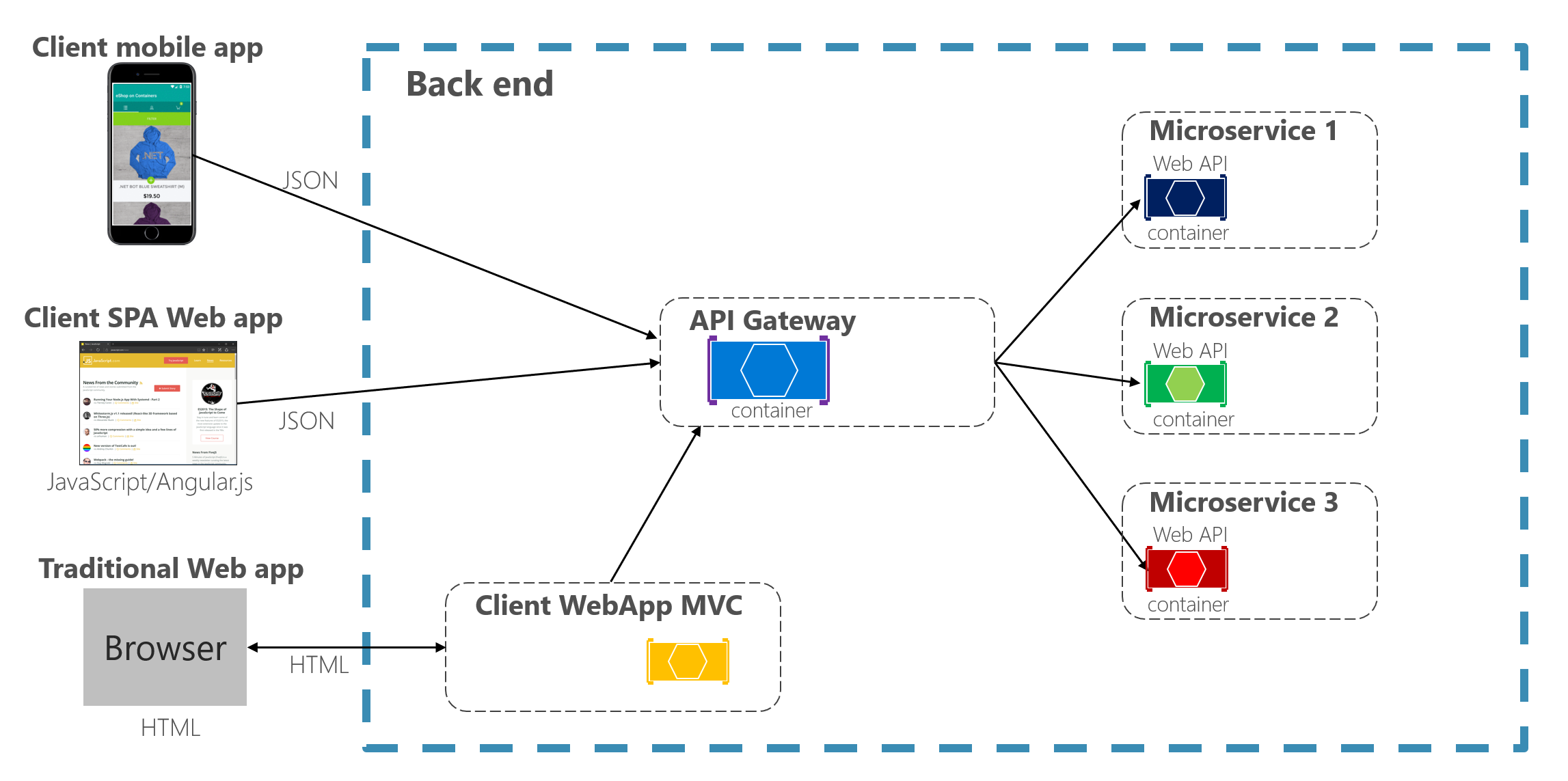
API Gateway
API Gateway Features
API gateway provides a single entry point to access microservices and facilitate following features:-
-
Reverse proxy or gateway routing The API Gateway offers a reverse proxy to redirect or route HTTP requests to the endpoints of the internal microservices. The gateway provides a single endpoint or URL for the client apps and then internally maps the requests to a group of internal microservices. This routing feature helps to decouple the client apps from the microservices.
-
Request aggregation As part of the gateway pattern you can aggregate multiple client HTTP requests targeting multiple internal microservices into a single client request. This pattern is especially convenient when a client page/screen needs information from several microservices. With this approach, the client app sends a single request to the API Gateway that dispatches several requests to the internal microservices and then aggregates the results and sends everything back to the client app. The main benefit and goal of this design pattern is to reduce chattiness and round-trips between the client apps and the backend API.
-
Cross-cutting concerns or gateway offloading. Depending on the features offered by each API Gateway product, you can offload functionality from individual microservices to the gateway, which simplifies the implementation of each microservice by consolidating cross-cutting concerns into one tier. This is especially convenient for specialized features that can be complex to implement properly in every internal microservice, such as the following functionality:
- Authentication & Authorization
Authentication and Authorization is done at API gateway level and services do not need do further check.
API gateway authenticates incoming request by evaluating OAuth token given by OAuth authentication server on successful authentication. This OAuth token can be used in subsequent requests. After successful authentication API gateway authorize the request using access token (eg, send in custom HTTP header). Based on authorization, gateway route the request to services. - Logging, debugging
API gateway logs each incoming requests and outgoing response to centralized logging system where other microservices also push their logs. API gateway generates a request_id for each incoming request which is passed through all the microservices serving that request. Any request can be traced end to end using this request_id. - Response Caching
API gateway can use caching mechanism for some of the request to provide response without routing request to underlying microservices. - Load balancing
API gateway can load balance incoming request if multiple instances of same microservice is running. - Retry policies, circuit breaker API gateway can provide a fault tolerant system by implementing retry policies and circuit breaker.
- IP whitelisting
Advantage of API gateway is that you need to provide only one IP for whitelisting when distributing APIs to thirdparty if required. - Encryption
API gateway can provide encrypted communication to clients while underlying microservices communication remain unencrypted. API gateway decrypts the incoming request, route to microservices, encrypt the response and send to clients. - SSL Certificate management
API gateway communication can be secured by providing SSL certificate to clients since API gateway is exposed whereas underlying microservices can communicate without SSL certification under a secure network.
- Authentication & Authorization
API Gateway - Cross Cutting Concerns
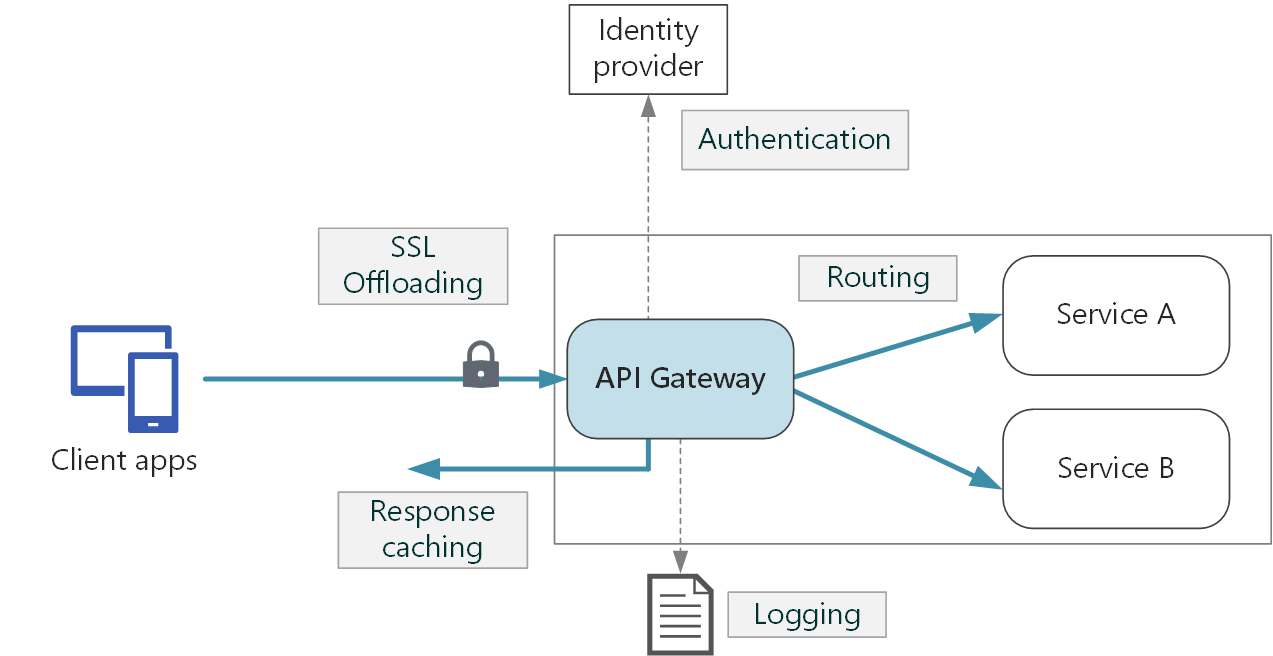
API Gateway - Cross Cutting Concerns
Netflix Zuul is one of the implementation of API Gateway pattern.
Backend for Frontend (BFF)
When you have multiple API gateways and each API gateway provide different API tailored for different clients app then this pattern is called Backend for Frontend (BFF) pattern.
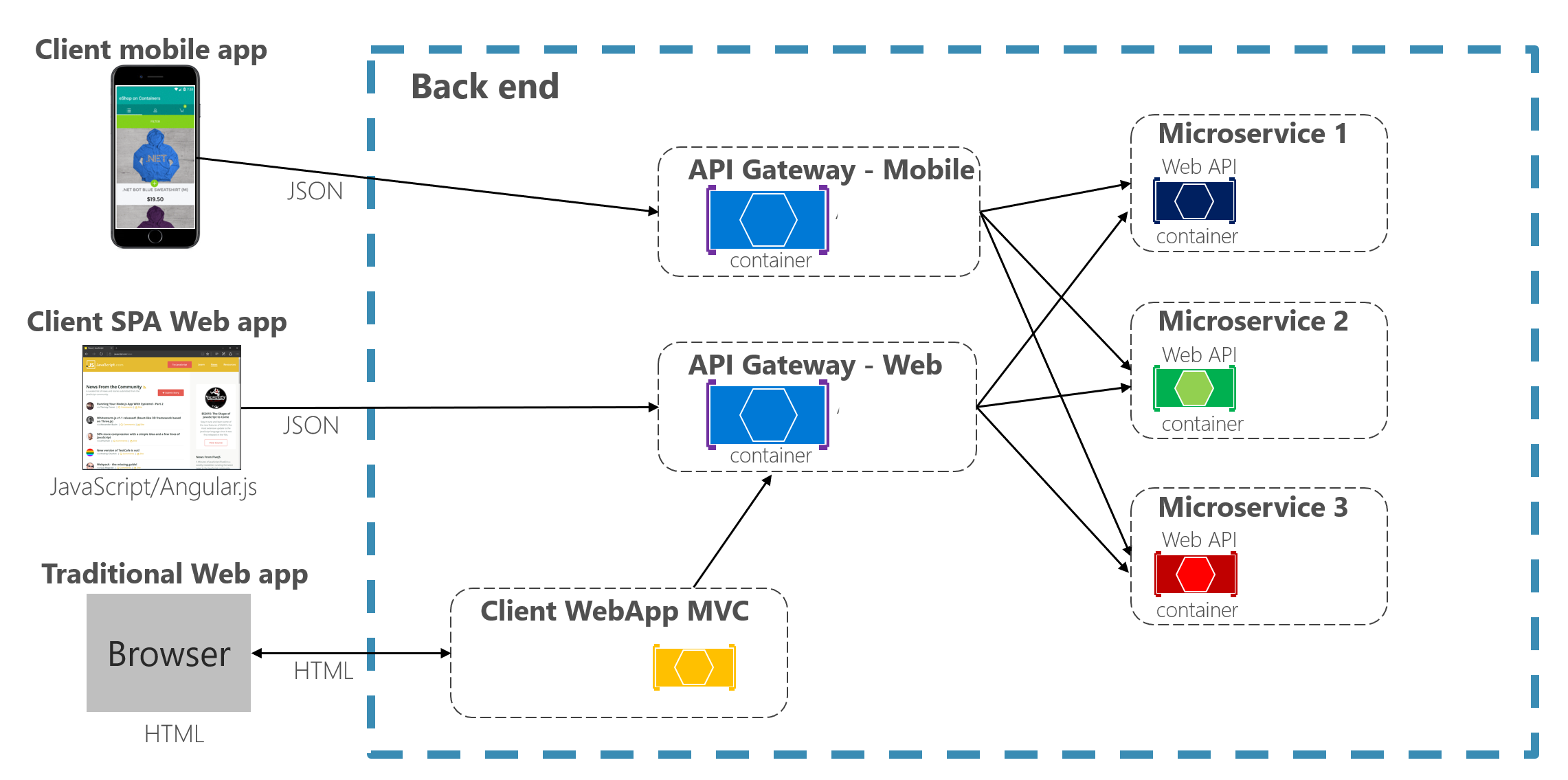
Multiple API Gateways - Backend for Frontend (BFF)
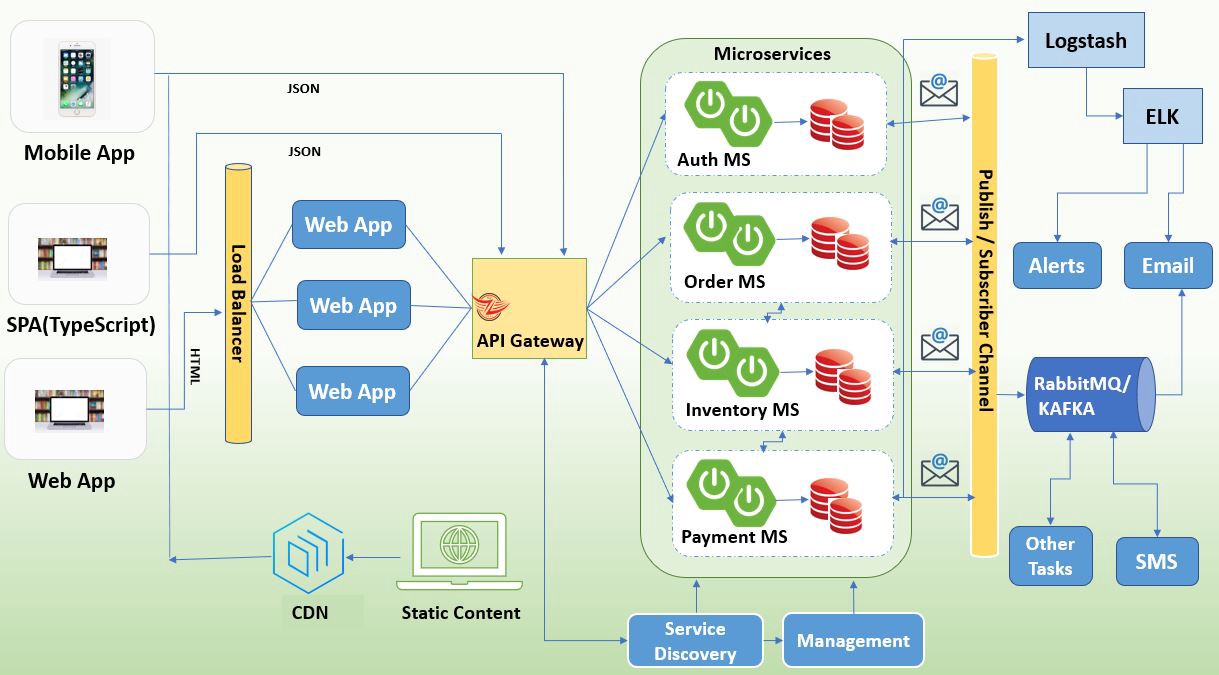
Q14. Could you explain a high level microservice architecture ?
Microservice High Level Architecture
The diagram say it all, Let’s see them one by one:
- Client — Client can be a Mobile App, Dynamic Single Page Web Application using Angular, ReactJS, Vue, WebComponents or any traditional clients which renders HTML.
- CDN (Content Delivery Network) — CDN is a system of distributed servers or networks of servers in locations all over the world. It delivers content from the website or mobile application to people more quickly and efficiently, based on the geographic locations of the user, the origin of the webpage, and the content delivery server.
- Load Balancer (Hardware/Software) — If there is a high value of incoming traffic and it is affecting system performance and ultimately user experience, application traffic needs to be distributed evenly and efficiently at multiple servers in a server farm. The load balancer sits between client devices and backend servers, receiving and then distributing incoming requests to any available server based on the load balancing algorithm such as Round Robin, Weighted Round Robin, Random, Least Connection, Weighted Least Connection, etc.
- Web Apps — Clients like Mobile App or SPA can talk to API gateway directly whereas traditional clients can talk to API gateway through load balanced web apps which are hosted on any web server like Apache, Tomcat, Heroku, etc.
- API Gateway (Zuul) — It’s a server that provides single entry point to talk with microservices. It offers reverse proxy for request routing and request aggregation. It is also responsible for cross cutting concerns such as Authentication & Authorization, logging, Response caching, Encryption, SSL certificate management, rate limiting, spike arrest. Any request coming from clients first go through the API Gateway after that it routes requests to the appropriate microservice. Netflix Zuul provides implementation of API Gateway.
- Service Discovery (Eureka) — Service Discovery holds the information like IP address, running port about all the microservices under applications. Microservice registers themselves with discovery server when up and running. Netflix Eureka provides implementation of Service Discovery.
- Management — Management Endpoints (Actuator endpoints) allow you to monitor and interact with your application. Spring Boot actuator includes several built-in endpoints and you can also add your own. Like, the health endpoint provides basic application health information. It’s widely used by containers to check the health and other parameters of the application.
- Microservices — These microservices are designed around business capabilities, can be deployed independently and loosely coupled. Communication among themselves happens through rest call.
- Event Bus (Kafka, RabbitMQ) — Event buses are used in microservices based application to avoid messy communication network and keep the communication across microservices clean, loosely coupled, non blocking, asynchronous. Event buses are nothing but a publish/subscribe system like Kafka, RabbitMQ which are used for async tasks like notifications, alerts, background jobs etc to improve performance significantly.
- Logging and Monitoring (ELK, Splunk) — Microservices based applications requires a centralized logging and monitoring system. One client request could be served by many services all together. In case of any failure, we need to track the request flow end to end across microservice, and this is where logging and monitoring tools helps like ELK (Elastic Search, Logstash and Kibana), Splunk, Grafana.
Q15. What is 12 Factor App ?
The Twelve-Factor App is a mythology for writing microservices. Following is an easy to understand summary of those 12 factors:-
1. Codebase
One codebase, multiple deploys.
We should have only one repository for each microservice in our source control such as git, subversion. All the microservice deployment should be from that repository.
2. Dependencies
Explicitly declare and isolate dependencies.
We should use dependency manager in our microservice such as maven (pom.xml) or gradle (build.gradle) for Java. Benefit is new developer can check out code onto their machine, requiring only language runtime and dependency manager as prerequisite.
3. Config
Store config in the environment.
We should create a Spring Cloud Config Server to manage configurations of all microservices across all environments like dev, staging, prod.
We should not declare configuration inside source code because configuration varies across deployments but code does not.
4. Backing services
Treat backing services as attached resources.
We should integrate microservice with resources like datastores, messaging systems, caching system or other microservices from the configuration only. All the resource URL, locator, credentials should come from configuration no matter if it is a thirdparty resource or developed by your organization.
5. Build, Release & Run
Strictly separate build and run stages.
We should use release management tools like Jenkins to create pipelines to separate the build (building executable by compiling source code), release (executable with configuration) and run (deployment of release to specific environment) stages.
Release should have a unique id such as timestamp or version like v1.0.0 which can not be mutated. Any change must be a new release.
6. Processes
Execute the app as one or more stateless processes.
Microservice we build, should be stateless and should not rely on in-memory cache or filesystem to store data since it usually wiped out on restart. Any data that need to be persist must be stored in backing service like database. However distributed cache like memcache, ehcache or Redis can be used.
We should also never use and rely on “sticky sessions”.
7. Port Binding
Export services via port binding.
We should always create a standalone microservice using spring boot which is having embedded Tomcat or Jetty webserver. As soon as service starts, it is ready to serve over HTTP by binding to a port. We should not rely on creating a war and then deploying to webserver.
8. Concurrency
Scale out via the process model.
Each microservice in application should be able to handle more load by scaling out (deploying multiple copies on microservice behind load balancer).
9. Disposability
Maximize robustness with fast startup and graceful shutdown
We should try to minimize the startup time of microservice and handle the shutdown gracefully. Microservice should be able to start and stop at moment’s notice to facilitate fast elastic scaling, rapid deployment of code or config changes.
10. Dev/Prod parity
Keep development, staging, and production as similar as possible.
We should adapt CI/CD (Continuous Integration/Continuos Delivery) by combining DevOps automation tools like Jenkins to build pipelines, Docker to containerize build with all dependencies, Chef and Puppet to automate delivery process. CI/CD process minimize the gap between development, testing, staging and production environments.
11. Logs
Treat logs as event streams
Microservice should not manage log files itself, instead treat it as event stream and route it to a centralized log indexing and analysis system such as Splunk or ELK (Elastic logstash Kibana) or data warehousing system such as Hadoop/Hive.
12. Admin processes
Run admin/management tasks as one-off processes
All admin/management tasks for a microservice like database migration should be deployed and run separately.
