 Coding N Concepts
Coding N Concepts Build Your First AWS DeepRacer Model
Build Your First AWS DeepRacer Model
This step-by-step guide is helpful for beginners trying their hands on machine learning and creating their first AWS DeepRacer model.
Prerequisite
You should have a valid AWS account. If you haven’t registered to AWS already, follow this Step-by-step guide to create an AWS Account
What is AWS DeepRacer?
AWS DeepRacer is an exciting way for developers to get hands-on experience with machine learning.
In AWS DeepRacer, you use a 1/18 scale autonomous car equipped with sensors and cameras. You can use this car in virtual simulator, to train and evaluate. The same car is used in physical AWS DeepRacer global racing league.
In AWS DeepRacer, You do this:
- build your car, or choose existing one,
- create your own reinforcement learning model, or choose from sample models,
- choose pre-defined racing track,
- train and evaluate your car on racing track using your model , and
- finally you compete with others.
Reinforcement learning
Reinforcement learning (RL) is an area of machine learning concerned with how an agents should take actions in an environment in order to maximize the notion of cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Let’s understand the reinforcement learning key terms from AWS DeepRacer perspective:
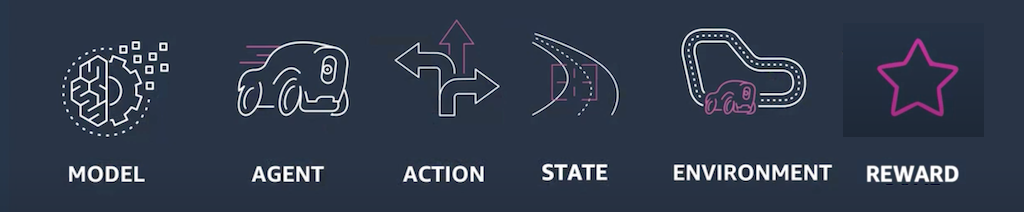
AWS DeepRacer Key Terms
- model is created when you choose a car, racing track and write your reward function.
- agent is your Car
- action space is the amount of choices a Car has, for e.g., turn left, turn right, move forward at different speeds.
- state is position of Car on the track at a point of time.
- environment is the Racing Track of your Car
- reward function is a function written in python which returns reward in floating point number. Your car use this reward function in its training and try to accumulate more reward points
- training phase is when you train your car on racing track using the model you created.
Also known as exploration phase where your car explore the racing track, and learn from which route it can get more reward points. - evaluating phase is when you evaluate your car after training is completed whether its able to complete the racing track or not. Also known as exploitation phase where your car exploit the learning from training and try to reach the convergence (finish line).
- The hyper parameters are reinforcement algorithm and training specific parameters which controls the car training process.
- You car make attempts to find the best route by accumulating reward point in training phase. Attempt starts either from the start line or any part of the track. Attempt ends when car reaches the finish line, or loose the track, or crash. Each of this attempt is called an episode.
Reward function
Reward function is a python function where you give higher reward points for good behavior and lower reward points for bad behavior.
Here is sample reward function written in python which gives higher reward points to car for keeping it wheels on track:
def reward_function(params):
# Read input parameters
all_wheels_on_track = params['all_wheels_on_track']
if all_wheels_on_track:
reward = 1.0 # higher reward for car to be on track
else
reward = 1e-3 # lower reward for car to go outside track
return float(reward)
When you train your car, it attempts to run at different angles and speed on the track and try to accumulate reward points. In each subsequent attempts, it learns from its previous attempts and try to accumulate more reward points by keeping it wheels on track.
1. Getting Started
① Go to AWS Services ➞ AWS DeepRacer ➞ Reinforcement Learning ➞ Get Started
② If it is your first time, you will see some errors. Don’t worry. Choose Reset Resources and everything will be fine.
AWS DeepRacer Get Started
This takes about 5 minutes. AWS internally does following things for you:
- Check IAM roles required for DeepRacer,
- Check AWS DeepRacer resource stack:
- Amazon SageMaker and AWS RoboMaker are the brain behind training your model
- Amazon S3 to store samples and the new models created by you
- Amazon Kinesis Video Streams for streaming data and simulation video, when your car is training and evaluating
- Amazon CloudWatch to store and analyze the logs and metrics
You should be well-aware of the AWS services involved in AWS DeepRacer in order to understand the billing when AWS charge you money. Here is the AWS DeepRacer Simulator Architecture:
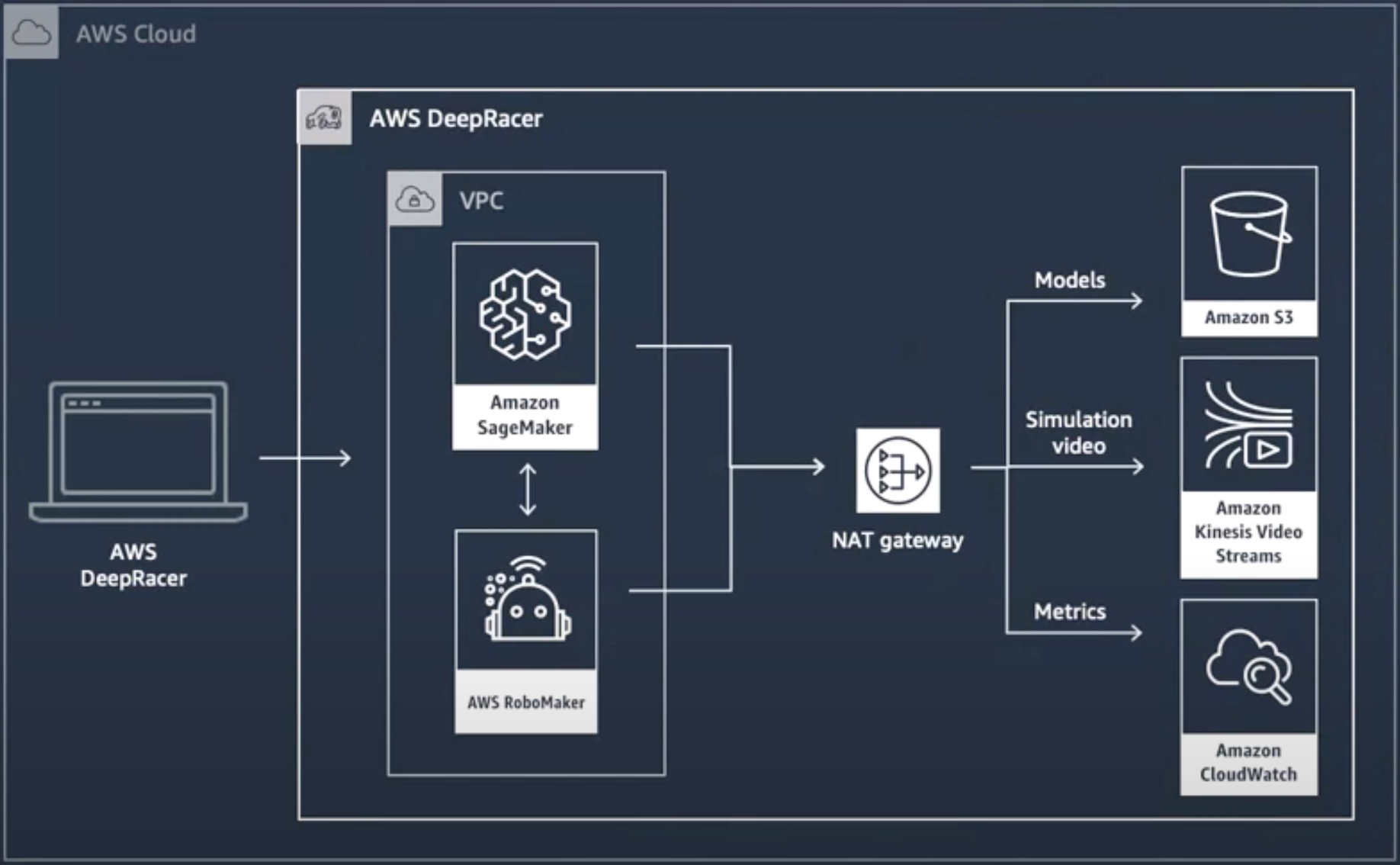
AWS DeepRacer Simulator Architecture
2. Build your Car
You can either use the default Car The Original DeepRacer or build a new vehicle by following these steps:
① Go to AWS DeepRacer ➞ Reinforcement Learning ➞ Your garage and Choose Build New Vehicle
② Keep the default setting of Camera and Sensors. Choose Next
③ Keep the action space settings as below. Choose Next
AWS DeepRacer Action Space for Beginners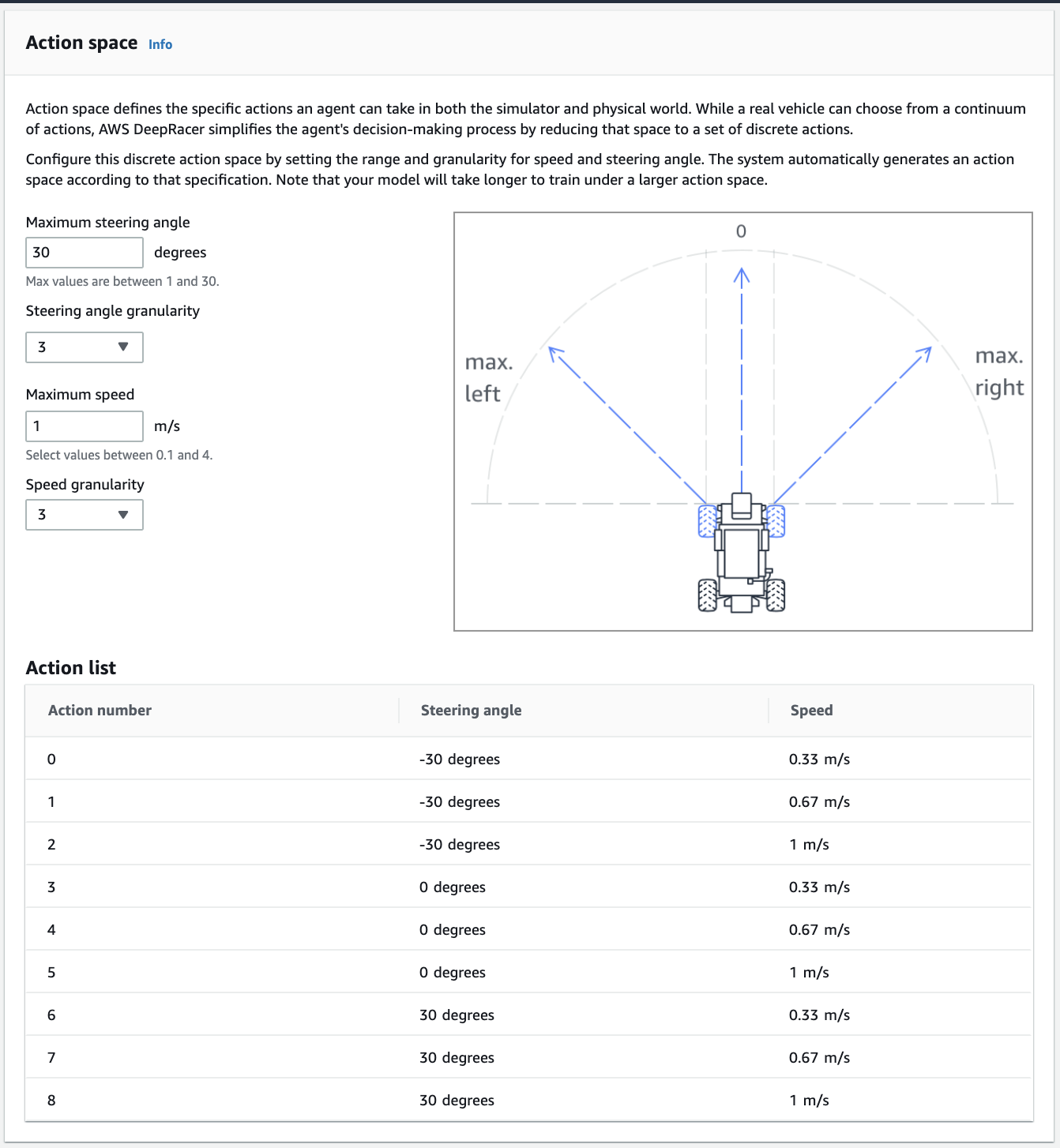
④ Enter the name of your car and Choose color. Choose Done
Action Space
You car can turn left, turn right, move forward at different speeds. All these choice become the action spaces of the Car. Action space of a Car depends on following parameters:
- Maximum Steering Angle: Max values are between 1 and 30.
- Steering angle granularity: Possible values are 3, 5 and 7
- Maximum speed: Select values between 0.1m/s and 4m/s.
- Speed granularity: Possible values are 1, 2 and 3
If you choose 5 Steering angles granularity and 3 Speeds granularity then it has total (5*3) = 15 action spaces (all combinations of angles vs speed). A car choose random action out of these 15 action spaces in its trail and errors.
Action Space = Steering angles granularity * Speeds granularity
Note that more the action spaces, more the choices a Car has to choose from. You might get the best finishing time and best time around the curve with more action spaces but it requires a lot of training and your Car might not reach the convergence (finish the racing track). Same is applicable for maximum speed.
As a beginner, it is advised to use:
- 3 steering angles and 3 speeds to start with (3*3) = 9 action spaces
- maximum speed to 1m/s to train your car faster.
Your primary focus while training your car should be on the accuracy and reliability of your model and not the speed or lap time of your Car. Once you have some insights, you can train your car by increasing the action spaces and max speed.
3. Create Model
There are five out of the box models available to use in AWS DeepRacer:
| Name | Description | Status | Sensors |
|---|---|---|---|
| Sample-Head-to-Head | Model trained with reward function for head to head racing | Ready | Stereo camera, Lidar |
| Sample-Object-Avoidance | Model trained with reward function that avoids objects | Ready | Stereo camera |
| Sample-Time-Trial-PreventZigZag | Model trained with reward function that penalizes the agent for steering too much | Ready | Camera |
| Sample-Time-Trial-StayOnTrack | Model trained with reward function that incentivizes the agent to stay inside the track borders | Ready | Stereo camera |
| Sample-Time-Trial-FollowCenterLine | Model trained with reward function that incentivizes the agent to follow the center line | Ready | Camera |
I recommend to click on each model, Go to their Training Configuration ➞ Reward Function and Action Space which will give you an idea on how to design your own model.
Let’s create our own model:
① Go to AWS DeepRacer ➞ Reinforcement Learning ➞ Your models and Choose Create Model
② Enter Model name and description
③ Choose a Racing Track. To follow with me, Choose ⦿ re:Invent 2018 and Choose Next
④ Choose a Race Type. To follow with me, Choose ⦿ Time trial
⑤ Choose an Agent (Car). To follow with me, Choose a car which we created earlier. Alternatively Choose default car “The Original DeepRacer”
⑥ Clear Reward Function Code Editor. Copy and Paste following reward function in code editor and Click Validate to make sure this code is valid.
⑦ Keep the default setting of Training Algorithm ⦿ PPO and hyperparameters.
⑧ Enter Stop Condition ➞ Maximum time = 60 minutes.
Note: Congratulations, You’ve configured your model. Next step is to create, train and evaluate your model. Please note that you have not charged anything till this point. Subsequent steps will charge you money based on AWS resource utilization.
⑨ Once you choose Create Model. AWS resources will be provisioned to train your model for 60 minutes.
Reward Graph
It is recommended to watch the reward graph and simulator video stream while your car is training. This was a thrilling experience for me to watch the live training of car using my first ever machine learning model.
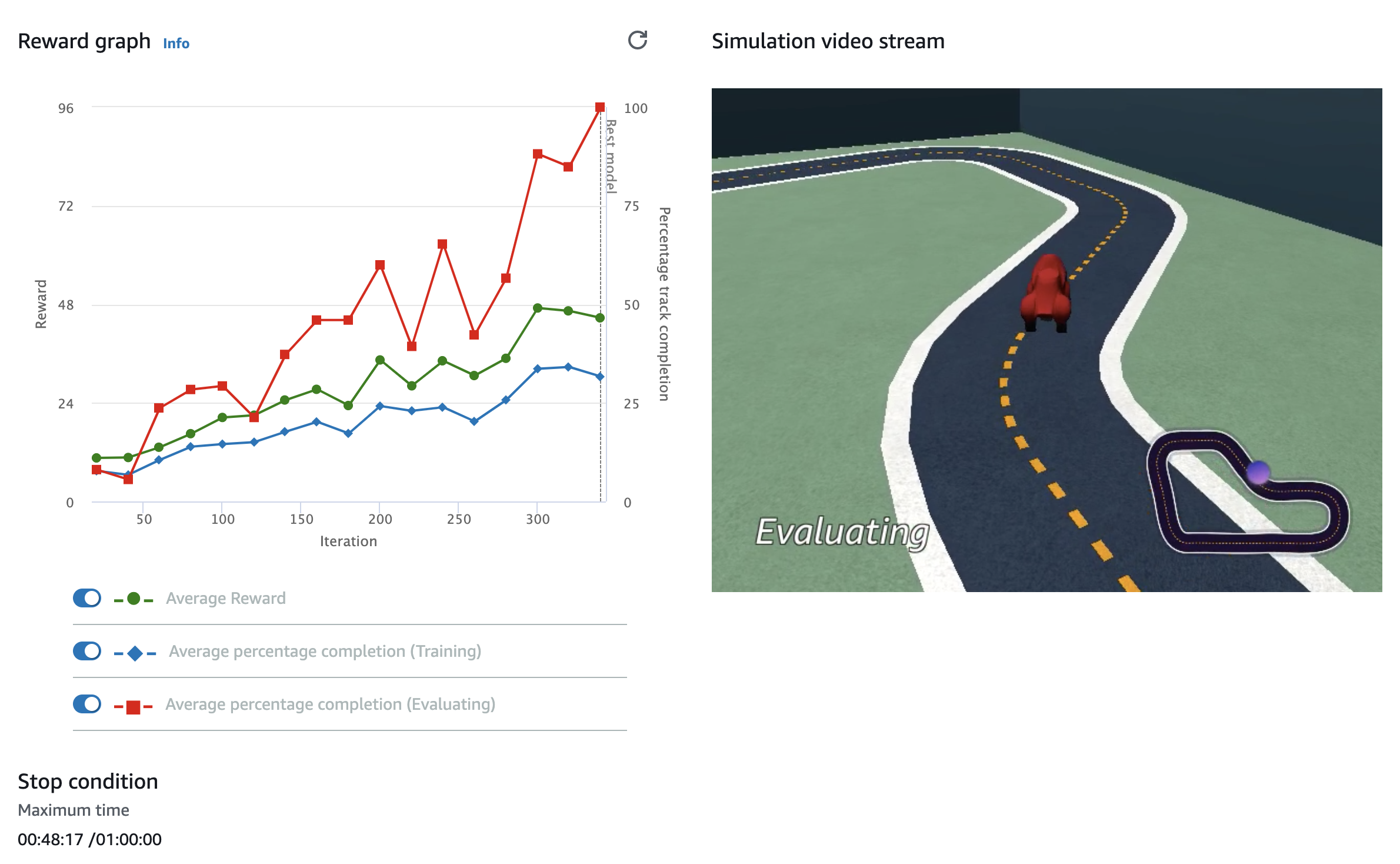
AWS DeepRacer Reward Graph and Simulator Video Stream
You should know how to read the reward graph in order to understand your model behavior:
- Average Reward is reward points your car is accumulating in each attempt. Average reward line should go up linearly in the perfect scenario but this is rare. This is what you should look:
- Average Reward line should go up in the longer time period. That means your car is able to learn from its past failures and able to accumulate more reward points in subsequent attempts.
- If Average Reward line go down in shorter period then do not worry. That means your car is trying to attempt those directions which return less reward points. Your car would learn from those attempts and won’t try them again in subsequent attempts.
- There are two phases when your car is training, you will notice them if you are watching simulator video:
- Training Phase: Your car trains on different parts of the racing track by starting at random positions.
- Evaluating Phase: You car starts from the starting point of racing track and try to complete the track.
- Average percentage completion (Training) is percentage of track completed in training phase. Since in training phase, main aim of car is to train at different parts of the track, it doesn’t complete the track most of the time and hence the graph line remain below and doesn’t touch 100% marker.
- Average percentage completion (Evaluating) is percentage of track completed in evaluating phase. Since in evaluating phase, main aim of car is to complete the track, it should touch the 100% marker and able to finish the racing track. If this graph line is not touching 100% marker then there are higher chances of your model failing in actual race.
Hyperparameters
Tuning the hyperparameters can improve the quality of your model but it requires a steep learning curve and a lot of trials and errors. As a beginner, it is advised to use default optimized parameters but at the same time, it is good to know how they impact the training of your Car.
- Number of episodes per iteration: Each attempt made by car in training phase is one episode. With Default value, a Car make 20 attempts in one iteration before updating training data to the network.
- Batch Size: Iterations runs in batches. Batch size controls, how many iterations to be completed before updating training data to the network.
- Number of Epochs: Number of times to repeat the batches and send optimized training data to network. Larger number of epochs is acceptable when the batch size is large.
- Learning Rate: Controls the speed your car learns. Large learning rate prevents training data from reaching optimal solution whereas Small learning rate takes longer to learn.
- Entropy: It is a degree of randomness in the Car’s action. Larger the entropy means the more random actions a Car will take for exploration.
- Discount Factor: It is a factor specifies how much of the future reward contributes to the expected rewards. With larger discount factor, Car looks further into the future to consider rewards. With smaller discount factor, Car only consider immediate rewards.
Take a quick look at hyperparameters:
| Hyperparamter | Advantage of higher values | Disadvantage of higher values | Default |
|---|---|---|---|
| Batch Size | More stable updates | Slower training | 64 |
| Number of Epochs | More stable updates | Slower training | 10 |
| Learning Rate | Car learns faster | May struggle to converge | 0.0003 |
| Entropy | More experimental may lead to better results | May struggle to converge | 0.01 |
| Discount Factor | Model looks farther out | Slower training | 0.999 |
| Episodes | Improves model stability | Slower training | 20 |
Personal Experience
When i started making my first model, I thought that i will make my first model as master piece. I selected max out configuration i.e. max speed 4m/s and maximum action spaces and training period as 2 hours. It failed miserably. It was not able to finish the track even in 2 hours training period and the reward graphs were all going in wrong direction.
After that I used the model configuration and reward function as mentioned in the post and able to finish the track in 60 min training time. I, then increased the max-speed from 1m/s to 1.5m/s and able to finish the reInvent:2018 track in ~19 seconds.
I recommend:-
- Make you model with above example.
- Learn from the reward graph and simulator video.
- Take one step at a time say increase the max-speed from 1m/s to 1.5m/s and train again.
- Continue to progress…
Thanks for Reading. I am still in learning phase of AWS DeepRacer and keep updating this post based on my new findings.
